О чистом рандоме

В перерывах между сохранениями артов с аниме девками
Однажды в пятницу на презентациях проектов, преподаватель во время презентации одного из проектов по machine learning высказался по поводу модели рандомного выбора. Решалась задача бинарной классификации то есть разделении инпута на две категории: хорошие данные или плохие данные. Так вот, когда были представлены замеры разных моделей, одной из них была модель подбрасывания монетки и определение результата просто из рандома. Эта модель показала результат чуть больше 0.5, что и возмутило преподавателя. Как он заявил, если монетка выдает хоть чуть чуть больше 0.5, то можно ее забустить и получить хорошую модель. Не задаваясь вопросом почему эта модель вообще была рассмотрена, попробуем разобраться так ли это.
Во-первых, лично я не понимаю претензий по этому поводу, потому что рандом на то и рандом что может выдавать результаты немного отклоняющиеся от теоретических данных. То есть моя гипотеза в том, что при увеличении количества прогонов рандомной модели, ее усредненные результаты будут стремиться к 0.5. Проверять эту гипотезу мы не будем, так как это просто одна из интерпретаций вероятности и стремиться она может очень и очень долго. Рассмотрим лучше вторую часть утверждения: монетку, которая предсказывает с шансом чуть лучше, чем 0.5, можно забустить и получить хорошую модель. Видимо предполагается, что монетка всегда будет говорить верный ответ с этим самым шансом чуть больше 0.5, что скорее всего неверно, но мы примем это как данность.
Итак сформулируем задачу: есть модель предсказывающая верный ответ с шансом 0.51 (те же расчеты можно провести с любой вероятностью меньше), нужно ее каким-то образом забустить так, чтобы получить «хорошую» модель, например, с шансом угадывания правильного ответа не менее 0.99 (опять таки его можно увеличить). Гуглинг по слову бустинга выдает какие-то алгоритмы в частности AdaBoost, но мне было лень читать тем более на википедии самого описания алгоритма я не нашел, а в кратком описании не разобрался так как не очень разбираюсь в терминах machine learning. Зато в гугл картинках нашлась такая схема: первая картинка по запросу machine learning boosting
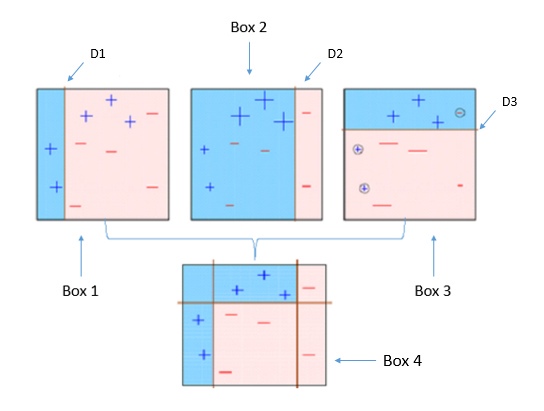
Так как мне интереснее по таким схемам додумывать алгоритм, чем читать его описание, которое тем более подразумевает обучение моделей, которого у нас нет, я решил разработать забущеную модель на основе следующего алгоритма:
- Возьмем очень много монеток и подбросим их для данного инпута
- На основе большинства монеток выдадим результат
Как видно на картинке используется именно такой алгоритм: выделяются синим только те зоны, за которые проголосовали не менее двух из трех первых моделей.
Итак возьмем например 195 (совершенно случайное число) монеток и опробируем вышеописанный алгоритм на 1000 случайных данных:
one_layer: 0.61909090909090913612544682109728455543518066406250
Такой шанс угадывания выдает новая мета-модель (весь код будет в конце статьи, так что вы можете проверить результаты сами). Это конечно не желаемые 0.99, но уже значительно лучше. Дальше я подумал, что теперь имея модель выдающую 0.61, можно забустить и ее ровно тем же самым образом. Действительно, возьмем 109 (тоже совершенно случайное число) новых «мета»-моделей и применим к ним тот же алгоритм и прогоним их тоже на 1000 данных (больше ideone не успевал):
two_layer: 0.99090909090909096157417934591649100184440612792969
Вау, действительно получилось. Теперь можно разобраться почему так получилось и привести PoC код (хотя я сам как раз делал сначала расчеты а потом запустил модели для эксперименты).
Допустим исходная модель давала вероятность \(p\) выдать правильный ответ. Тогда проведя эксперименты по описанной выше схеме с нечетным (чтобы точно определить, что один из результатов превалирует) количеством исходных моделей, получим, что вероятность модели из n монеток имеет шанс угадать ответ:
Так как сложно оценить эту сумму, посчитаем ее на ЭВМ при p = 0.51 при различных n (тут я бы мог вставить график зависимости суммы от n, но мне лень):
| \(n\) | value |
|---|---|
| \(187\) | \(0.60791510268042203701810421989648602902889251708984\) |
| \(189\) | \(0.60847479697657635977492418533074669539928436279297\) |
| \(191\) | \(0.60903132281386229696096279440098442137241363525391\) |
| \(193\) | \(0.60958472862817358883802398850093595683574676513672\) |
| \(195\) | \(0.61013506161391062310173083460540510714054107666016\) |
| \(197\) | \(0.61068236776822715228263405151665210723876953125000\) |
| \(199\) | \(0.61122669193325396275184857586282305419445037841797\) |
| \(201\) | \(0.61176807783643771809778399983770214021205902099609\) |
| \(203\) | \(0.61230656812907802155621084239101037383079528808594\) |
| \(205\) | \(0.61284220442316794663639711870928294956684112548828\) |
Видим, что эта сумма растет медленно, но превышает 0.6 уже на 195 монетках. Окей, как и описывалось возьмем эту модель и посчитаем ту же сумму уже при p = 0.61:
| \(n\) | value |
|---|---|
| \(93\) | \(0.98437112503143087138823830173350870609283447265625\) |
| \(95\) | \(0.98524806965791367208140627553802914917469024658203\) |
| \(97\) | \(0.98607387745086494401647314589354209601879119873047\) |
| \(99\) | \(0.98685169738443523357318554189987480640411376953125\) |
| \(101\) | \(0.98758446909873343066976758564123883843421936035156\) |
| \(103\) | \(0.98827493833300716907785954390419647097587585449219\) |
| \(105\) | \(0.98892567106284867683996253617806360125541687011719\) |
| \(107\) | \(0.98953906646756828457967003487283363938331604003906\) |
| \(109\) | \(0.99011736883963319399981628521345555782318115234375\) |
| \(111\) | \(0.99066267853564293766055470769060775637626647949219\) |
Тут уже рост гораздо быстрее и также мы наконец видим желаемые 0.99 на 109 моделях.
Дальше хочется проверить эту модель с 195 монетками на первом «уровне» и с 109 «метамоделями» на втором «уровне», посчитать ее фактический результат, матожидание и дисперсию среди 1000 прогонов (мало так как мы имеем 109*195 = 21 255 работающих монеток на один запуск модели):
| expected | \(0.98999999999999999111821580299874767661094665527344\) |
| variance | \(0.00989999999999987938259504716143055702559649944305\) |
Бабах, модель работает очень неплохо, по сравнению с начальной монеткой.
Какой же вывод из всего этого можно сделать? Во-первых забустить слабый алгоритм machine learning несложно, и тогда появляется вопрос о применимости техник бустинга и вопрос зачем выбирать модели и архитектуры, если их всегда можно забустить. Вряд ли быстродействие является значимым препятствием для такой схемы. Далее, если исходить из предположения, что монетка, угадавшая на нескольких прогонах 0.51 тестовых данных, далее всегда будет угадывать не хуже, то действительно пробрасывание монетку кучу раз это эффективная модель machine learning. Даже если она дает ответы реже, чем 0.5, то ее результат можно инвертировать(так как у нас задача бинарной классификации) и получим монетку, с шансом больше чем 0.5. То есть если мы отрицаем, что подбрасывание монетки это достойное решение задачи machine learning, то либо неверно предположение: монетки иногда угадывают чаще, чем 0.5, а иногда реже, либо же мы ошибаемся. Значит при верности предположения (которое я думаю, что неверно) преподаватель был прав и модель монетки должна давать ИДЕАЛЬНЫЕ 0.5 на любых данных.
Код
calcs.py — вычисление суммы, поменяйте p для расчетов для другой исходной модели
import math
def nCr(n,r):
f = math.factorial
return f(n) // f(r) // f(n-r)
p = 0.51
for nn in range(1000):
s = 0
n = 2 * nn + 1
for k in range(nn + 1, n + 1):
s += (p ** k) * ((1 - p) ** (n - k)) * nCr(n, k)
print("%d: %.50f" % (n, s))
models.py — описание и тестирование моделей в виде лямбд
from random import random
def get_majority(s):
s = list(s)
return 0 if s.count(0) > s.count(1) else 1
def test_model(model):
x = (0 if random() <= 0.5 else 1)
prediction = model(x)
return (prediction == x)
def test_average(model, tests_count):
s = 0
for _ in range(tests_count):
s += test_model(model)
return s / tests_count
# model slightly better than just flip coin, accuracy: 0.51
nice_roll_model = lambda x: (x if random() <= 0.51 else 1 - x)
# one layer model with expected accuracy 0.61
one_layer_model = lambda x: get_majority(nice_roll_model(x) for _ in range(195))
# two layer model with expected accuracy 0.99
two_layer_model = lambda x: get_majority(one_layer_model(x) for _ in range(109))
# expected: 0.51
res = test_average(nice_roll_model, 1000)
print("nice_roll: %.50f" % (res))
# expected: 0.61
res = test_average(one_layer_model, 1000)
print("one_layer: %.50f" % (res))
# expected: 0.99
res = test_average(two_layer_model, 1000)
print("two_layer: %.50f" % (res))
RUNS = 1000
results = []
for _ in range(RUNS):
res = test_model(two_layer_model)
results.append(res)
expected = sum(results) / RUNS
variance = sum((x - expected) ** 2 for x in results) / RUNS
print("expected: %.50f" % (expected))
print("variance: %.50f" % (variance))