Мысли про обработку ошибок и структурное логирование в Go
Intro
Сегодня мы обсудим обработку ошибок в языке Go. Я считаю, что эта тема достойна внимания, потому что есть много аспектов, касающихся обработки ошибок, которые в разных вариантах и комбинациях в итоге применяются в проектах:
- Нужно ли оборачивать (wrap) ошибки? Когда их нужно/не нужно оборачивать?
- Если нужно, то как? Через
fmt.Errorf("error: %w", err), структуру вида Как-то еще? - В каком месте и какой вызывать логгер? В месте возникновения ошибки? В самом вверху в мидлваре grpc/http/etc? Везде?
- Какие сообщения должны быть в логгере? Какие сообщения должны быть для оборачивания ошибок? Какие поля нужно добавлять в сообщение ошибки, а какие в логгер?
- Как правильно строить структурное логгирование? Добавлять ли в лог место вызова? Стек трейс?
- Как использовать контекст: нужно ли через него прокидывать логгер или поля для запроса? Или логгер должен быть фиксированным для слоя (один для логики, один для бд и тд)? Или логгер должен быть один глобальный?
- Как обрабатывать ошибки? Как и когда использовать
err != nil,err == sql.NoRows,errors.Is(err, MyError),errors.As(err, &myError)? - Как и какие делать ошибки уровня слоя и sentinel ошибки? Как их обрабатывать?
- Как обработать ошибки, чтобы в конце концов выдать в http хендлере/grpc методе/etc корректный код и сообщение? Нужно ли в ошибку на уровне логики добавлять код http или как-то по другому?
- Как обрабатывать ошибки извне (от других http/grpc сервисов)? (это единственный вопрос, на который здесь не будет ответа)
Далее я расскажу, к какому способу обработки ошибок я пришел, и обосновать почему он самый логичный.
Что такое ошибка
Начнем с того, что есть ошибка. В языке Go, ошибка - любое значение, чей тип удовлетворяет интерфейсу
Такое описание ошибки говорит, что ошибка это просто строка, которую можно в любой момент получить через вызов err.Error(). Кроме этого, если мы знаем, что ошибка имеет конкретный тип, например
то, кроме сообщения типа "{.Message}: {.Err.Error()}" мы можем по отдельности получить err.Message и err.Err. Но только если это точно этот тип:
if err != nil {
if e, ok := err.(MyError); ok {
fmt.Println("MyError", e.Message, e.Err.Error())
} else {
fmt.Println("unknown error", err.Error())
}
}
Говоря проще, ошибки - это значения, из которых можно узнать информацию о деталях этой ошибке, и должным образом на нее отреагировать.
Паники
Для ошибок, после которых невозможно продолжать работу и которые, соответственно, нельзя разумно обработать, есть механизм паники. Его мы рассматривать не будем, так как с ним все очень просто:
- либо у нас есть мидлвара на
recover, которая красиво принтит ошибку с паникой (и желательно стектрейс) и продолжает работу сервиса - либо программа падает и кидает стектрейс нам в лицо
Как обработать ошибку
Ошибки же предназначены для того, чтобы их обработать. Если мы попытались прочитать файл, а его нет, функция чтения не роняет нам программу исключением или паникой, вместо этого она возвращает ошибку и дает возможность отреагировать:
- создать и заполнить искомый файл
- пойти читать другой источник данных
- вернуть ошибку
Очень много функций могут тем или иным образом пойти не так и придется обрабатывать их ошибочное поведение. Так, у нас постоянно выстраиваются цепочки вызовов, чтобы сделать какую-нибудь задачу, в конце которых возникает ошибка и вся цепочка должна на нее как-то отреагировать:
- пришел запрос на добавление тудушки
- запрос пошел на уровень бизнес логики, прошел валидацию
- запрос пошел на уровень репозитория
- запрос пошел в драйвер бд - драйвер бд отвечает ошибкой
- ???
Самый простой вариант
Самый простой вариант - вернуть пользователю ошибку. Как http хендлер узнает, что надо возвращать ошибку? Ее надо прокинуть через весь стек вызовов:
// на уровне репозитория
taskID, err := r.db.Insert(ctx, task)
if err != nil {
return 0, err
}
// на уровне логики
taskID, err := l.repo.Add(ctx, task)
if err != nil {
return 0, err
}
// на уровне хендлера
taskID, err := logic.Add(r.Context(), task)
if err != nil {
w.Code(500)
w.Write(err.Error())
}
Проблемы этого подхода:
- Много монотонного кода, кажется, что проще забить на все эти обработки ошибок, кинуть панику в репозитории и поймать в хендлере.
- На уровне хендлера непонятно, что за ошибка произошла, нет возможности выбрать соответствующий код HTTP/GRPC/etc.
- Пользователю прилетает ошибка вида
sql: Syntax error after ) on pos 43. Стоит ли говорить, что сообщение абсолютно ничего не говорит пользователю, кроме того, что что-то пошло не так. - В ответе пользователю может прилететь то, чего мы не хотим отдавать: какой нибудь драйвер бд напишет параметры подключения при неудавшемся подключении, выдаст запрос в бд а с ним и схему, или еще что-нибудь.
- О произошедшей ошибке мы узнаем только когда к нам придет недовольный пользователь, который соизволил написать багрепорт, техподдержка на него отреагировала и направила к нам и мы увидели это. Другой же пользователь может просто перестать пользоваться нашим приложением, или техподдержка ответит что-то вроде “перезагрузите и попробуйте еще раз” или сообщение об ошибке не дойдет до нас еще каким-нибудь способом.
- Даже если мы узнаем, что что-то пошло не так, и пользователь приложит запрос (очень повезет, если так) и ответ к багрепорту, мы сами по ответу можем не сразу сообразить что и где пошло не так.
Улучшенный вариант
Как мы будем справляться с этими проблемами (решений может быть множество, привожу одно из):
- Сразу положим в ошибку код возврата и сообщение для пользователя.
- Исходную ошибку залогируем, чтобы не потерять и отреагировать сразу. Так же залогируем место вызова, чтобы сразу найти, где в кода произошла ошибка.
Недостатки решения с учетом улучшений:
- Код загрязняется вызовами логгера во всех местах, где может возникнуть ошибка. То есть во всех, где вызывается чужой код. Не очевидно, где при отлове ошибки ставить лог, а где не ставить.
- Уровень репозитория знает про то, какие ошибки и какие сообщения должны отображаться из хендлера. Репозиторий не может этого знать, его обязанность - доставать данные/делать действия типо отправки почты. Реагирование на ошибку просочилось через все уровни с хендлера до репозитория.
- При логе в репозитории может быть недостаточно данных, чтобы мы отреагировали на ошибку. Например, в запросе приходит идентификатор пользователя и текст задачи, а до метода репозитория, который зафейлился, дошел только текст задачи. В логе мы увидим, что не добавилась задача с таким-то текстом, но у неизвестно какого пользователя.
Какие еще идеи могут придти, чтобы исправить эти недостатки, и что с ними не так:
- Добавлять стектрейс в ошибку. Выглядит слишком вербозно в логах и стектрейс нужно добавлять все так же только при вызове чужого кода. Изредка, тем не менее, оправдано.
-
Прокидывать значения запроса через контекст. Контекст был создан для отмены запросов/остановки горутин, добавлять в него еще и значения - неправильно:
- значения в контексте не типизированы, входит
any, выходитanyнужно руками кастовать обратно в нужный тип - сами значения могут вдруг отсутствовать в контексте, так что при доставании значения из контекста необходимо делать по две проверки: что значение есть и что значение нужного типа. Если про тип значений мы еще можем договориться и всегда передавать один типо по одному ключу, то ничто не мешает вызвать метод не после мидлвары, которая должна положить значение в контекст, а, например, в тесте
- нужны шаманства с
type ctxKey struct{}для корректной работы сcontext.Values
В итоге, во всех отношениях будет лучше передать значения запроса явно через аргументы: будет и типизация, и нейминги, и гарантии наличия полей.
- значения в контексте не типизированы, входит
-
Прокидывать логгер с значениями запроса через контекст не работает по тем же причинам.
- Прокидывать логгер с значениями запроса через аргументы приведет к тому, что с контекстом, все методы будут загрязнены еще и логгером. Если с данными запроса мы еще могли что-то делать, то с логгером только логировать. В конце концов, это приведет к абсурду, что в метод парсинга числа из строки придется тоже прокидывать логгер, чтобы залогировать ошибку вызова чужого кода (стандартная библиотека тоже чужой код).
- На уровне репозитория определить ошибки уровня репозитория и на уровне хендлера разобрать с помощью методов
errors.Is,errors.As. Плохо это тем, что теперь хендлер завязывается на репозиторий и полагается, что где то внутри логики точно вызовутся именно те методы, которые возвращают искомые ошибки. Вместо этого логично завязываться на непосредственно ошибки логики: хендлер проверяет ошибки логики, логика проверяет ошибки репозитория.
Конечное решение
Наконец, опишу свое решение, на основе всего вышесказанного:
- Каждый уровень определяет ошибки, которые на нем могут произойти. При этом необязательно определять типы для всех-всех-всех возможных ошибок, для тех, которые непонятно, как хендлить, можно ограничиться каким-нибудь
fmt.Errorfилиxerr.New(ниже подробнее о либеxerr). - Каждый уровень обрабатывает ошибки нижнего уровня или оборачивает, если не может обработать/хочет прокинуть ее наверх. Например, ошибка логина может выглядеть так:
- на уровне репозитория ищется хеш пароля по указанному
login, драйвер возвращаетsql.ErrNoRows - репозиторий возвращает
repository.ErrLoginNotFound - логика проверяет ошибку, если это
repository.ErrLoginNotFound, возвращаетlogic.ErrNotAuthorized - хендлер проверяет ошибку, если это
logic.ErrNotAuthorized, возвращает401 Unauthorized, иначе500 Internal Server Error
- на уровне репозитория ищется хеш пароля по указанному
- Чтобы найти место, где произошла ошибка, и добавить все необходимые данные, ошибки с нижнего слоя оборачиваются с добавлением сообщения о действии, которое не получилось сделать (именно действие, а не название метода) и дополнительные параметры этого действия, например:
В случае fmt.Errorf сложно говорить о какой либо структурности ошибок, поэтому приходится либо создавать кастомные типы ошибок с нужными полями, либо создавать одну общую ошибку с любыми возможными полями, как я сделал в своей библиотеке rprtr258/xerr. Тот же пример будет выглядеть так:
Из этой ошибки можно будет достать все поля и использовать для структурного логирования.
- Какие поля добавлять в ошибку. Отдельно ставлю этот вопрос, потому что при неправильном подходе легко добавить в структурную ошибку одни и те же данные несколько раз. А отслеживать что на каких уровнях добавляется и где что надо или не надо добавлять уже звучит сложно. Поэтому принцип такой: в ошибку добавляются параметры действия, полученные из аргументов метода (aka производные данные), но не сами аргументы метода. Идея в том, что у вызывающей функции и так есть доступ к аргументам, и, если надо, она сама их добавит при оборачивании. Те данные, которые были вычислены из аргументов, можно кидать в ошибку, ибо в вызывающем методе их нет. Чтобы было понятнее, приведу пример:
func newApp(filename string) (App, error) {
configData, errReadConfig := os.ReadFile(filename)
if errReadConfig != nil {
// не добавляем filename т.к. это аргумент
return xerr.NewWM(errReadConfig, "read config file")
}
config, errParseConfig := parseConfig(configData)
if errParseConfig != nil {
// при желании можно добавить configData или string(configData) т.к. является производным от аргументов
return xerr.NewWM(errParseConfig, "parse config data")
}
app, errApp := logic.New(config)
if errApp != nil {
// можно добавить config т.к. является производным от аргументов
return xerr.NewWM(errApp, "create app", xerr.Fields{"config": config})
}
return app, nil
}
- Сообщения к ошибкам при оборачивании обычно имеют вид “глагол существительное” (но может быть и другой), описывающее, что мы пытались сделать. Тогда итоговая ошибка будет содержать полностью действие, которое не получилось сделать, с причиной в конце:
authorize: find user: login not found, вместо вербозного сообщения с кучей повторов, типаfailed to authorize: can't find user: can't find login. Такие сообщения проще читать и они позволяют найти место (и трейс) где в коде произошла ошибка (если только мы пишем разные ошибки в разных местах, а не в десяти местахsomething failed). - Сама ошибка логируется на самом верхнем уровне (в мидлваре), при этом ошибка должна содержать весь нужный контекст и данные для структурного логгирования. Можно пользоваться любой удобной библиотекой для логирования, хоть logrus, хоть zap, хоть zerolog, хоть даже simple-go: log/slog. Лично я сделал свой rprtr258/log, чтобы он внутри структурно разбирал ошибку и красиво отображал все ее поля:
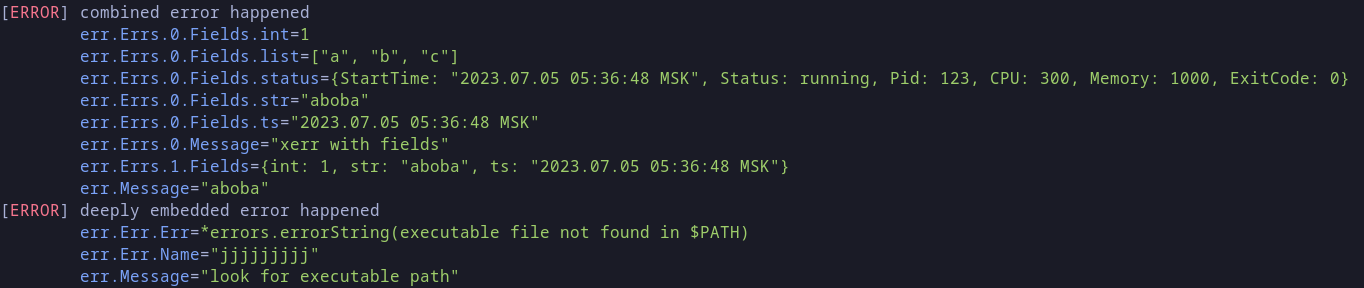
Затем я поменял ее на реализацию Handler-а для log/slog.
- Через контекст ничего не передается: ни логгер, ни данные. Максимум, возможно, что-то необходимое исключительно для отладки типо
trace_id. - Для проверки, что ошибки оборачиваются на каждом уровне, можно использовать линтер tomarrell/wrapcheck.
- Ошибки в коде именуются согласно действию, чтобы не допустить shadowing и обернуть случайно не ту ошибку. Пример наименования ошибок можно найти выше в сниппете с функцией
newApp. - Обработка ошибок состоит из проверки на тип/равенство. Если ошибка - sentinel константа, то через равенство, если нужно проверить тип для кастомной ошибки - через type switch или type assertion:
if err != nil {
switch err {
case logic.NotAuthorized:
w.Code(401)
default:
w.Code(500)
}
return
}
// или
if err != nil {
if _, ok := err.(logic.NotAuthorized); ok {
w.Code(401)
} else {
w.Code(500)
}
return
}
Подобная обработка полностью убирает надобность в функциях errors.Is и errors.As. Оборачивание же ошибок используется для сохранения структуры для логов и стакивания сообщений. Эти функции не нужны также в том смысле, что нет смысла лезть внутрь ошибки и завязываться на детали реализации, слой должен явно декларировать все возможные ошибки.
В идеале можно было бы избавиться от интерфейса error в возвращаемых типах и явное декларировать через тип-сумму, какие ошибки может вернуть функция. Развитие подобной идеи, как я понял реализовано в языке Zig.
Реклама
Для поддержки описанного стиля обработки ошибок я написал две библиотеки:
rprtr258/xerr - оборачивание ошибок, добавление структуры, по желанию добавление стектрейса, caller-а, нескольких вложенных ошибок
rprtr258/log - хендлер для log/slog, чтобы разворачивать структуру ошибок и красиво ее печатать
Минусы конечного решения
- не могу придумать, как без кастомного логгера полностью извлекать поля из вложенных ошибок, а не только из самой верхней и нужно ли это вообще
References
Идея вдохновлена следующими статьями:
Wrapping errors in Go: A new approach
Также недавно увидел статью на эту же тему